
The cheapest AI stack is rarely all-local or all-cloud
The usual framing for LLM costs is cloud versus local. It sounds neat, but it misses where most of the savings actually come from. The real game is tokenomics: deciding which requests deserve expensive tokens, which can be handled by cheap or free models, which should stay local, and which should never be generated at all. That is why the most cost-efficient stack is usually not “all local” or “all cloud.” It is a routing policy. OpenRouter’s own docs lean into exactly this idea with auto-routing, free-model routing, fallbacks, and prompt caching, all aimed at reducing unnecessary spend.
Cloud pricing is now low enough to change the break-even math
Cloud has become cheap enough that local no longer wins by default on price alone. Current official list pricing puts OpenAI GPT-5.4 mini at $0.75 per 1M input tokens and $4.50 per 1M output tokens; Anthropic Claude Sonnet 4.6 at $3 per 1M input and $15 per 1M output; Google Gemini 2.5 Flash at $0.15 per 1M input and $1.25 per 1M output; and Gemini 2.5 Flash-Lite at $0.10 per 1M input and $0.40 per 1M output. OpenAI also publishes lower batch pricing for some models, Anthropic advertises up to 90% savings with prompt caching and 50% with batch processing, and Google prices context caching separately for Flash and Flash-Lite.
Current price floor: cloud models worth comparing
| Option | Input price | Output price | Cost levers |
|---|---|---|---|
| OpenAI GPT-5.4 mini | $0.75 / 1M | $4.50 / 1M | Cached input $0.075; Batch pricing available |
| Anthropic Claude Sonnet 4.6 | $3.00 / 1M | $15.00 / 1M | Prompt caching and Batch |
| Gemini 2.5 Flash | $0.15 / 1M | $1.25 / 1M | Context caching priced separately |
| Gemini 2.5 Flash-Lite | $0.10 / 1M | $0.40 / 1M | Cheapest official price floor here |
| OpenRouter | Depends on model | Depends on model | 300+ models, 25+ free models, routing/fallback, caching |
All figures in the table above come from the current official pricing pages. OpenRouter’s pricing page says pay-as-you-go gives access to 300+ models, the free plan includes 25+ free models, pay-as-you-go carries a 5.5% platform fee, and failed fallback attempts are not billed when routing is enabled.
What local actually costs
Local feels “free” only if you ignore capital cost, power, and maintenance time. The community still treats the used RTX 3090 as a sweet spot because 24GB of VRAM is enough to make a lot of open models practical, and recent Reddit pricing discussion put a good used one around $623 in at least one local-market example, while others in the same thread said U.S. market prices were often materially higher. That makes local attractive, but not free.
A simple reference box shows how this plays out. Take $1,000 of hardware amortized over 24 months, plus a 250W GPU used 5 hours a day. At the current U.S. average residential electricity price of 17.45¢/kWh, that power works out to about $6.54 per month, which puts the monthly local cost around $48.21 before counting your time. That is not outrageous, but it is high enough that low-cost cloud models can still win for light or moderate usage.
The community does not agree that local is automatically cheaper
This is exactly where homelab and LocalLLaMA discussions split. On one side, builders argue that self-hosting rarely wins if you compare only hardware against a subscription or low-end API bill. One self-hosted commenter put it bluntly: “In isolation proprietary LLM will always be cheaper and better for general purpose.” On the other side, local-first users argue that cloud pricing is strategically unstable, that privacy and autonomy matter, and that bulk token generation can be dramatically cheaper once the hardware is already in place. In one LocalLLaMA thread, a user running 2×3090s said they had generated 200M tokens in a week for about $10 in power, and that many smaller-model workloads came out 4–5× cheaper locally, though they also noted that bigger models are closer to break-even and often still better in the cloud for throughput.
That tension is the key insight for the article: the answer is not “local is cheaper” or “cloud is cheaper.” The answer is that different workloads have different break-even points. Heavy overnight jobs, repetitive batch processing, and privacy-sensitive internal workflows can tilt local. Casual chat, low-volume automation, and hard reasoning can still tilt cloud.
Latency is a trade-off, not a clean win
Local is not automatically faster. It is often just more predictable. OpenRouter’s docs say routing improves reliability but that latency can vary by model, provider, and region, and they explicitly recommend pinning a specific model and region if you care about consistent latency. Local systems, meanwhile, have their own latency profile: slow prompt processing on large contexts, GPU memory limits, and throughput constraints unless you parallelize aggressively. Community benchmarking discussion also points out that power tuning matters: one Reddit thread noted that a 3090 capped around 250W can outperform dual 3060s while staying more efficient in real inference use.
The best savings usually come from model selection, not model loyalty
This is where OpenRouter becomes important. It is less useful to think of it as “another provider” than as a routing layer. OpenRouter says it gives one API over 300+ models, does not mark up provider token pricing, supports auto-routing, preferred vendor selection, prompt caching, and fallbacks, and only bills successful runs when fallback routing is enabled. It also offers a Free Models Router that automatically selects from currently available free models. That turns the remote side of the stack into a cost-optimization surface instead of a single-provider commitment.
That is a much stronger money-saving story than “go fully local.” Cheap or free models can handle routing, summarization, extraction, first-pass drafting, and routine coding scaffolding. Mid-tier models can handle solid everyday reasoning. Premium frontier models can be reserved for hard judgment calls, debugging, and final-pass review. Good tokenomics comes from escalation discipline: not spending top-tier tokens on bottom-tier work.
Why task mix matters more than ideology
The token load is wildly different depending on what you ask the system to do. A short email or regex prompt is cheap. A contract summary, PR review, meeting transcription, or 100-page filing summary is not. That is why the same pricing model can feel trivial for one workflow and punishing for another. The onprem.ai “LLM Token Usage in Everyday Office Tasks” dataset is useful here because it estimates token usage across 64 real-world tasks, spanning communication, coding, analysis, planning, document processing, and multimodal workloads. It shows, for example, that a short email might consume around 150 total tokens on a standard model, while summarizing a 100-page regulatory filing can climb to 42,000 standard tokens or 92,000 total tokens on a reasoning-style model.
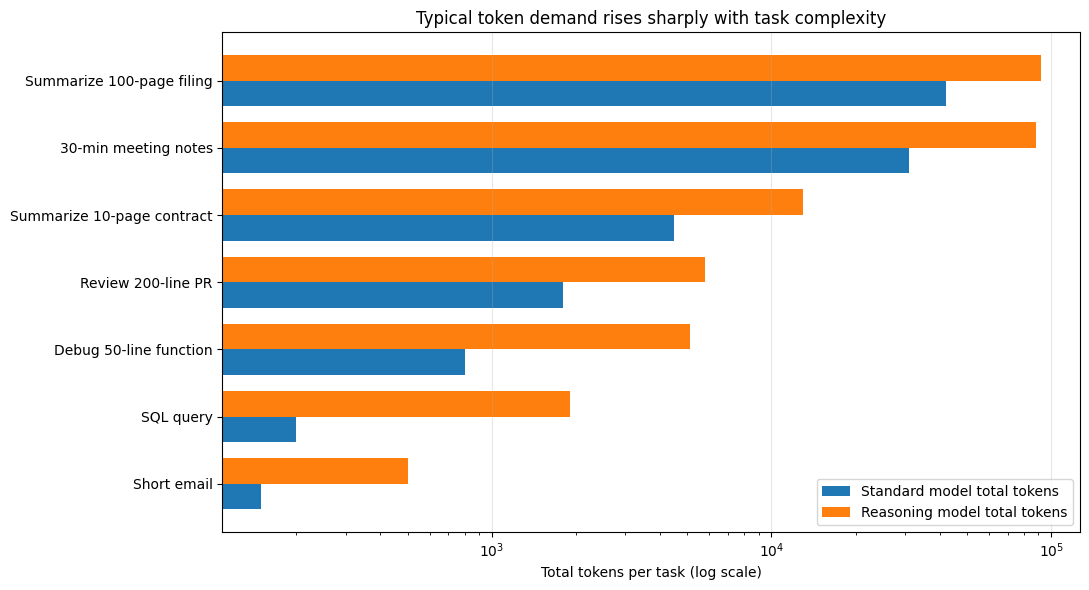
I created that chart from the onprem.ai task dataset, using representative examples across everyday office, coding, and document-heavy workloads. It is not a universal benchmark, but it is a good visual reminder that “one prompt” is not a meaningful unit of cost. The task mix matters far more than the raw count of API calls.
The forward-looking move is to treat AI as a platform
Once you start thinking in tokenomics instead of camps, the architecture changes. The goal is no longer to force everything local or send everything to one cloud provider. The goal is to create a control plane that can decide, task by task, where each request belongs. That is the logic behind platform-style stacks. QUI’s public docs describe QUI Core as a local gateway coordinating memory, workflows, characters, and model routing, including local models through Qllama and remote models through its broader LLM bridge. In a setup like that, adding a router layer such as OpenRouter to the cloud side gives you a much wider model pool without changing the overall policy: local for fixed-cost and private work, cheap remote for overflow and first pass, premium remote for escalation.
A practical cost-saving policy
The cheapest stack for most serious users is usually:
- Local first for repetitive, private, and high-volume work.
- Cheap cloud second for burst capacity, specialized open models, and lightweight automation.
- Premium cloud last for genuinely hard reasoning or high-stakes output.
That policy matches both the economics and the community experience. The people getting the best savings are not simply “going local.” They are getting far better at deciding which tokens are worth spending.
The real conclusion
The strongest economic case for local models is not that cloud has become unaffordable. It is that bad model selection wastes money faster than almost anything else in the stack. Local hardware can absolutely save money when usage is heavy enough, private enough, or repetitive enough. Cloud can absolutely stay cheaper for light usage, occasional hard tasks, or teams that do not want the maintenance overhead. The winning move is not to pick a side. It is to build a system where cheap tokens do cheap work, expensive tokens do expensive work, and the rest never get generated at all.